
放烟火的人生而平等:对 AI 产品落地的讨论

今年 3 月的 NVIDIA GTC 上,看到了 NVIDIA 发布的最新架构的芯片,不由感慨算力发展速度之快。某种程度上,NVIDIA 从自己的角度给出了摩尔定律的破解方案。正如五年前 Dave Patterson 在 A New Golden Age for Computer Architecture 演讲中提出过,传统架构的同构计算模式已经走向终结,很快就会受到物理制成的限制,但 DSH(domain-specific hardware) 必将兴起。GPU 作为异构计算中最有代表性的产品,也确实在 AI 时代展现了足够强大的能力。
不过今天,我想聊的并不是关于算力和硬件的问题。而是软件和系统的角度思考一个非常严肃的话题。理论上,人类是有充足的算力和硬件去支持各种 AI 应用的,但是现在并不是每一个人都有能力去制作自己想要的模型,去用 AI 成功的创业,将 AI 模型转化成理想的产品。几个月前,我刚刚读完了《枪炮、细菌与钢铁》。书的开篇序言,作者和一个新几内亚的土著 Yali 进行了对话,提出了一个引人深思的问题:Î
Why white people developed so much cargo and brought it to New Guinea, but we black people had little cargo of our own?
同样的问题也再次发生在了 2024 年的今天,为什么所有和 AI 相关的创新产业几乎集中在美国。在美国更容易看到繁荣的 AI 创业文化和开发文化?而不论是欧洲,还是中国,AI 相关的创新产业不论是数量还是质量上,都很难达到同样的水平。
在接下来的时间里,我希望对这些问题进行系统的讨论和分析:
- 制约 AI 应用发展的限制有哪些
- 一个 AI 模型,距离产品化还有多远的距离
- 一个 AI 产品,如果要盈利,有多少阻碍和难度
- 基于 AI 的 App 发展趋势是怎样的,对传统系统架构有什么挑战
- 让 AI 应用落地的一些可能性
Por Una Cabeza —— 时代之舞中的一步之遥
作为一个 AI 领域相关的科研工作者,在探讨这些问题之前,我希望更换一个看问题的视角,作为一个软件开发者和创业者的角度来看看这件事。当然,我没有任何成功的经验,只有失败的教训,只能站在失败者的角度给大家分享一些思考角度。
Por Una Cabeza,是我最深刻的感触,当我们和 AI 共舞的时候,看到 AI 的强大的一面的同时,忽略了实验室产物和产品之间的「一步之遥」。
参数设置
我接触的第一款有商业化潜力的 AI 产品是 Stable Diffusion。后来,该类目中的 Mid Journey 也比较成功的完成了初步商业化。然而,尽管有 Mid Journey 这样的成功产品,我们还是不得不承认 AI 生图目前还处在发展初期。作为非专业和非严肃领域的设计,确实达到了「可用」的程度。但是生成的图片距离「稳定」还有不小的距离,而且不同模型之间的「完成度」差异也非常大。
那么在这个品类发展了两三年之后,该品类的核心问题还没有改变。我们姑且看一下当下最常用的 AI 绘图工具,webui 的界面:
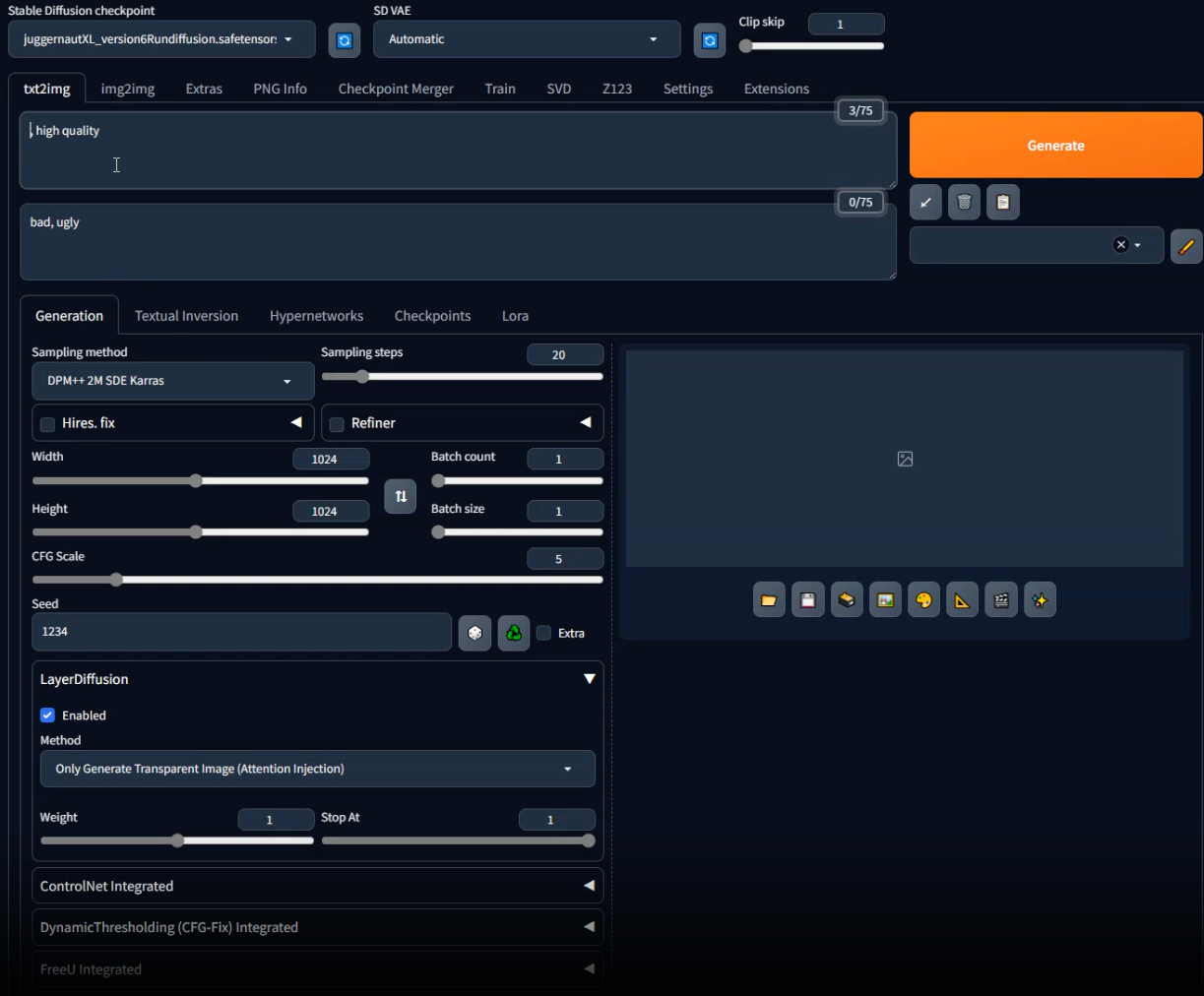
其中需要设置的东西包括:模型、参数、采样方法等数十个参数。如果需要控制图片的一部分,还需要加入例如 controlnet 等插件。这种设计明显不是为了给消费者使用的。如果要熟练掌握所有参数的调整方法,熟练地使用 AI 出图,确实需要几小时个到数十个小时不等的学习时间,而且,对于非 AI 领域研究人员来说,理解参数这种过程确实并不是那么的友好。
同样,也是因为近期的开发需求,我接触到了另一个基本上已经完成「内卷」的赛道:语音转文字(speech-to-text)。这个赛道已经有了明显的榜单,也有比较成熟的方案了,然而,现在的消费产品又是什么样子的呢?
一个比较成熟的开源产品:Subs AI。他也有同样的问题,参数效果同样复杂,需要选模型,设置合适的参数。
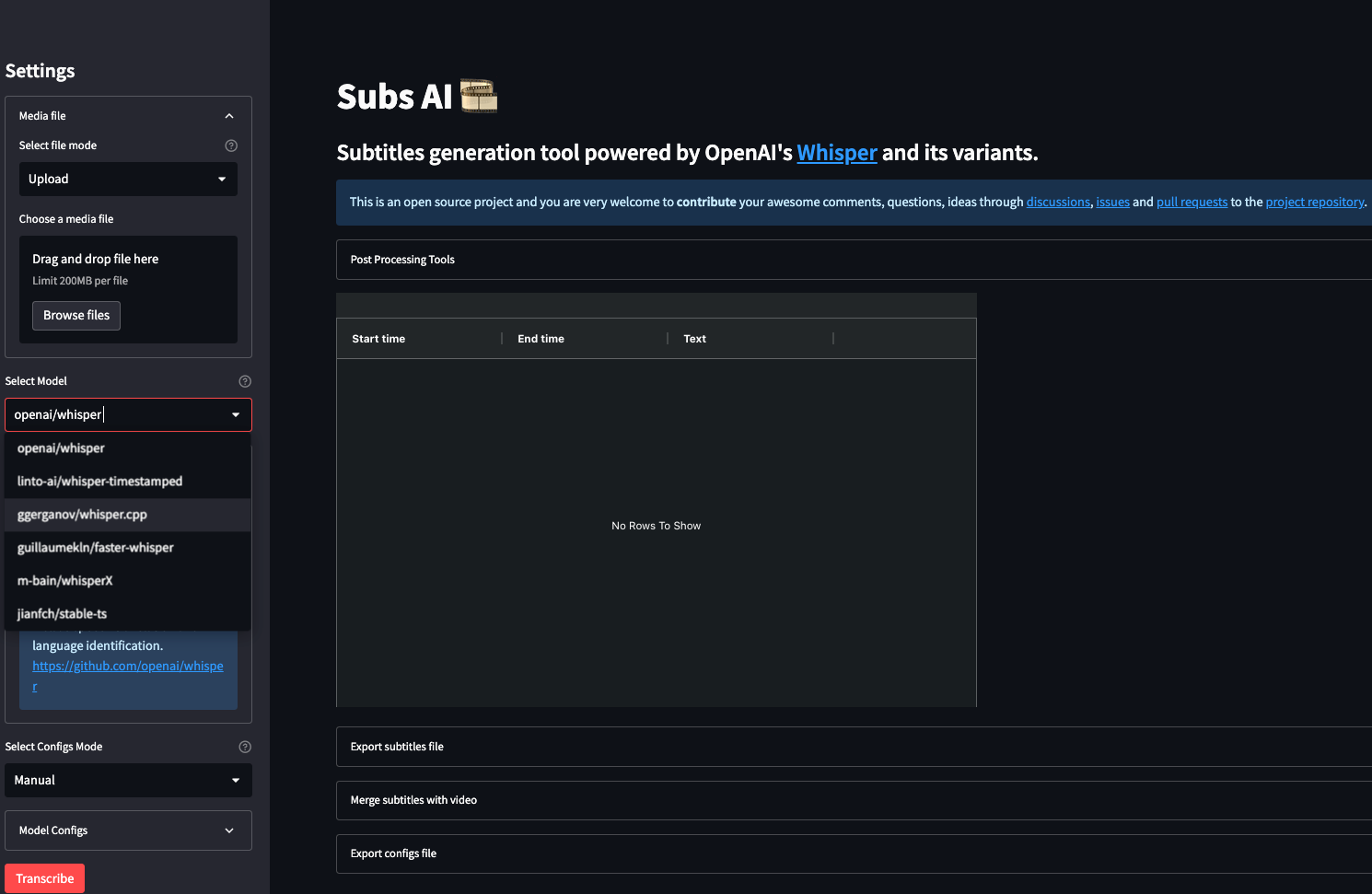
我们再看一些商业化的产品的实例,例如 SuperWhisper,界面就相对成熟和简洁了很多:
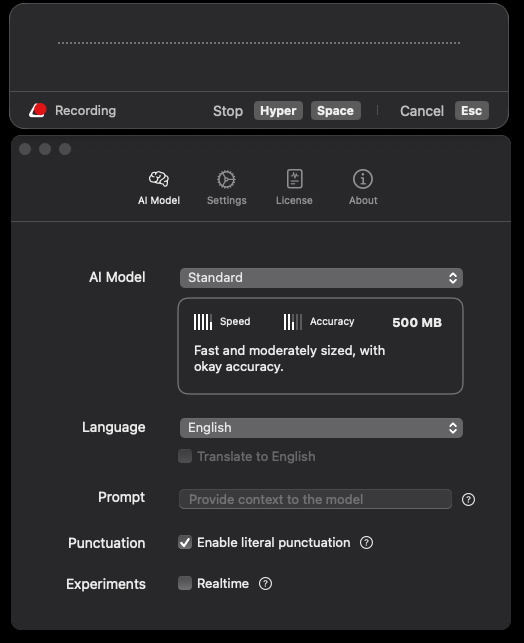
不难看出,到这个时候,产品已经进行比较合适的「参数设置」,对产品简化的负面效果就是失去了产品的自由度,不能全面地对各种产品适配。如果包装到这种程度,产品已经非常僵化了,用户失去了一些自由调整的空间。如何找到一个平衡,是 AI 产品需要思考的一个重要问题。
完成度
我的个人观点中,大众喜欢的产品,最重要的一个设计是「简洁」。参数设置问题中,我们的「无为」并不意味着让圈养用户,而是用更隐晦和潜移默化的方式,提升用户的体验效果。
在前 AI 时代,我个人最为喜欢的产品其实是 Google。不论何时,他都是我最有力的科研工具和利器。但对大众用户来说,我们直接输入自己的问题,基本可以获得我们需要的一切信息。对于专业用户,我们也可以通过复杂的约束条件组合,找到更加精确符合自己期望的结果。用同一个接口,同样的产品逻辑,让不同专业程度的用户同时受益,简洁精炼。目前位置也没有可以取代 Google 在我日常生活中地位的产品。
「无为」设计,并不是我们什么都不做,而是做了足够多的情景设定,对不同的用户场景和用户行为进行充分思考,让用户「无为」。
OpenAI 的 GPT 系列无疑是贯彻落实这一理念的最成功产品,专注「对话」这一件事情。如果是高阶用户,也开放编程接口 API 以及各种高阶功能,例如 fine tune。但是对于普通用户来说,「对话,然后解决问题」,这就是他们唯一需要的东西了。刚刚结束的 OpenAI 发布会上,在发布了 GPT-4o 之后,GPT 非常成功的降低了从「提出问题」到「给出答案」之间的距离,是目前为止世界上「end-to-end」最成功的典范。除了模型能力还是比较局限,OpenAI 应该给出了 AI 助理最为理想的形态。
此外,OpenAI GPT、Claude.ai、Mid Journey 这类成熟的商业化产品,最大的成功之处,我认为其实是产品生成效果的完成度。虽然他们也有不尽人意的时候,但是总体而言,他们生成出来的东西基本上是稳定可用的,作为 AI 产品具有极高的完成度。文心一言有时候需要复杂的 prompt engineering 去调整最终的输出结果,Stable Diffusion 也需要复杂的调参测试才能拿到非常满意的图片。从试错成本上来看,他们似乎并没有那么的「完整」。并不是说他们不好,而是他们的使用需要用户花费更多的学习成本和时间成本,距离「好用」还有「一步之遥」的距离。
破局尝试
从产品角度来看,「参数过多」和「完成度」是 AI 产品最大的两个问题。对于 OpenAI 的大型企业,可以使用人力资源解决这个巨大的问题,通过考虑设计足够多的用户使用场景,从而简化大部分人的使用门槛。但是对于小公司来说,人力资源显然并不是一个可取的方案。这里我们可以换一个角度来思考这个问题。
首先看参数,参数问题是因为模型本身的复杂性导致的,大模型时代的模型确实比之前的「图片分类」「图像分割」要复杂许多。很难通过几个参数表述模型的全部细节。目前大多数企业的解决方案都是通过对特定的场景调好参数,用户可以直接使用预设参数完成自己的任务。例如刚刚的转写,用户关心的可能只有语言这一件事情,其他的参数调整好可以设置成为不同的价位。
不过也有一种懒人方案,那就是让用户「直观」理解每个参数的效果和含意。我之前留意到一个非常有趣的例子是可以通过具体的例子展示参数的效果,用动态文档的形式辅助用户理解。
Stable Diffusion QR Code 101 [^1]给出的例子:
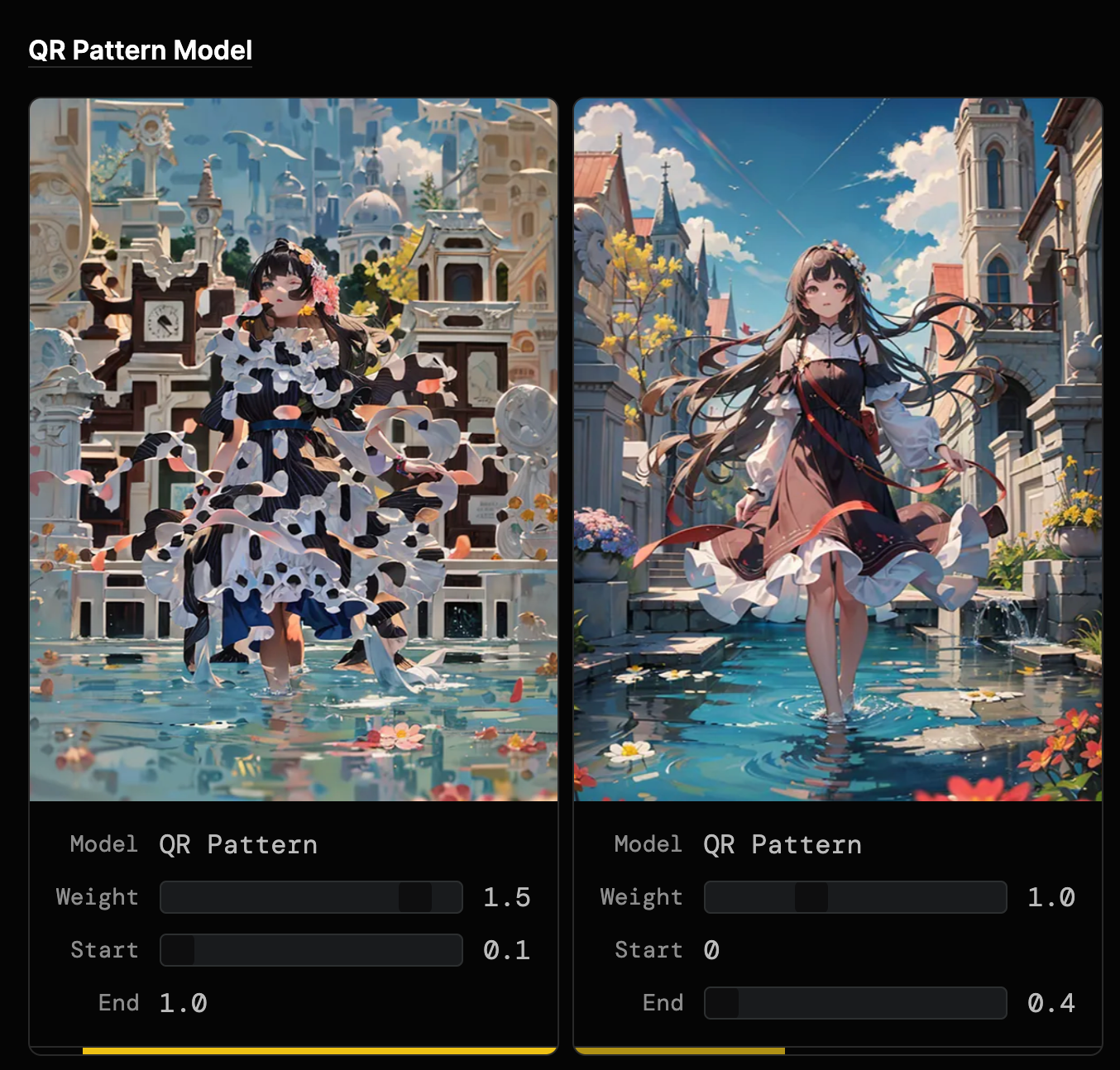
通过动态交互 demo 的形式可以非常直观地理解参数含意。不过这种方法也不是万能的,AI 画图中的「迭代次数」和「优化器选择」等比较隐晦、不直观的参数很难直接让用户理解含意。
所以,目前看来这个问题还是会长期存在。未来一种可能的方案是通过小模型的介入,让用户和小模型交互之后,生成合理的参数,继而接入下一个模型环节。(好吧,抱歉这段时间太懒了,一直没空写 blog,最近看到 Omost 确实是类似的思路。Omost 没有完全解决这一问题,但是降低了用户写高质量 prompt 的成本)
完成度则是另一个思考维度需要解决的事情。尽管大模型在各个领域已经初露头角,但稳定性和可靠性仍没有达到理想的水平。我们也不得不正视自己的问题,大模型并不是一切问题的通解。近期出现的 MOE(Mixture of experts) 是一种可能的出路,用效果较好的小模型拼接成大模型,从而用小模型逼近大模型的效果,以小博大。用这种思路训练出的 Mitral 就成功达到了近似大模型的效果,而且训练的成本和训练小模型几乎等价。但是具体的技术细节和 MOE 中的每一个 export 的训练其实也有一定的讲究,真正达到所谓「以小博大」还是有非常多技术困难的。
小结
虽然说,大模型时代已经来临,但是诸多问题依旧没有解决。主要来说是两点:
- 模型效果稳定性不能得到保障,会给客户带来潜在的额外开销
- 模型的模式单一,核心模块只有 Transformer 和 Diffusion 两种类型,对多模态效果依旧不好
- 模型的效果水平对使用者要求极高,需要对模型参数有具象化的理解能力
上述的问题也是限制大模型产品产出的问题,不过这些其实都是算法上的问题。我相信 AI 领域的研究人员很快就会给出我们满意的答案,近几个月诸如 Memba、非乘法 Transformer 等新结构不断涌现,我也对这些问题保持乐观态度。
但是乐观并不代表我们解决了产品的问题,模型好不代表产品好,其背后有一个重要的问题是模型的部署方案。这也是我这篇文章重点希望讨论的问题。
从理论到产品的距离
刚刚,通过对一些已有产品的观察,我们看到了现在 AI 产品的一些难点。但是作为开发人员,我们要将自己的模型成功的部署盈利,还有非常远的路要走。
首先,我们需要讨论 AI 应用中,最重要的一个问题:算力从哪来?
目前市面上常见的应用有两种方案:
- 买或者租一些服务器,部署应用
- 使用第三方 API
这个问题实际上对应的是几个问题的集合。首先算力的供应方案直接对应的是我们的设备成本,不同算力的成本是有区别的。其次是延迟,算力质量会直接决定 AI 产品生成的时间。最后是效果,算力设备的显存大小会直接限制模型的种类,从而限制模型的效果。
硬件开销
控制算力,我们实际上控制的是 AI 模型的部署后端。直接部署一个模型,我们需要考虑的细节问题会比较多,比如:
- 硬件资源:确定需要的算力资源,包括 CPU、GPU、内存等,并根据需求选择合适的硬件设备。
- 软件环境:确保所选硬件设备上安装了适当的操作系统和所需的依赖库,例如 TensorFlow、PyTorch 等。
- 模型优化:对模型进行优化,以便在部署时能够高效地运行。这可能包括量化、剪枝和压缩等技术。
- 并发处理:考虑到高并发的情况,需要确定系统能够同时处理多个请求,并避免出现性能瓶颈。
- 服务接口:设计良好的服务接口,可以方便地接收输入数据,并返回模型的预测结果。
- 负载均衡:在部署多个模型实例时,需要实现负载均衡,以确保每个实例都能够平均分担负载,并提供高可用性。
- 安全性和隐私:确保模型的部署后端具备安全性和隐私保护措施,例如身份验证、数据加密等。
- 监控和日志:建立监控和日志系统,以便及时发现和解决潜在的问题,并提供跟踪和审计的能力。
控制算力涉及到多个方面的细节问题,需要综合考虑才能确保模型的高效部署和运行。而在 AI 时代来看,部署难度是远远高于前互联网时代的。对于分布式部署服务,我们之前有 kafka 提供稳定的服务,有 redis 这种成熟的分布式数据库方案。但是在大模型时代,之前的方案都会被庞大的数据体量冲破失效。
在假设我们已经解决了服务器部署的各种问题之后,我们不妨估计一下成本问题。就用最基本的大语言模型作为场景,GPT 对 Token 的计算根据输入和输出有所差距,我们姑且按照平均价格计算,就是 $10.00/1M tokens [^2]。对应我们可以获得的毛利润。
而机器成本,对应的核心问题是:我们需要多少张 GPU?什么 GPU?
第一个问题是相对简单的,GPU 数量的决定因素是 GPU 显存的大小,如果能把模型放下来,算得慢些也无所谓。
$$ \text{GPU数量} = \frac{模型运行开销}{显存大小} \approx \lfloor \frac{模型参数量}{显存大小} \rfloor $$
模型参数量一个常见的估计方法,是 $X$ B 的模型需要 $2X$ GB 的显存开销,例如 LLaMA-7B 我们需要 14 GB 的显存开销。[^3]
(虽然有 Flexgen 和 PowerInfer 为代表的系列工作让小显存的电脑也可以快速进行推理,但是通用型不足,也对开发人员水平有一定的需求。我认为这种人才的人力成本是远远高于 GPU 的,哈哈)
第二个问题是影响我们成本控制的关键,用什么 GPU。
市面上大部分 GPU 机器的租金大部分是按照小时租赁的,单位一般是 $/h,我们不难换算得到 $/s 的平均每秒租金开销。
$$ \text{Token/$} = \frac{\text{计算速度(Token/s)}}{\text{机器租金($/s})\times \text{GPU数量}} $$
整理一下上面的公式:
$$ \text{成本(Token/$)} = \frac{\text{计算速度(Token/s)}}{\text{机器租金($/s)} } \div \lfloor\frac{\text{模型参数量(GB)}}{\text{显存大小(GB)}} \rfloor $$
我们这里可以用一个具体的例子做个评估:
如果使用 llama.cpp 项目在 4090 上运行 Qwen2 14B 的量化版本,需要的显存是 21.62 GB,正好放在一张 4090 上,推理速度是 63.71 tokens per second,我的测试平台是 vast.ai,定价是 $0.35/h
那么换算一下单位,我们的成本是:
$$ \text{成本(Token/$)} \approx \frac{63.71 ; \text{Token/s}}{0.35; \text{$/h}} = 63.71 * 3600 \div (0.35) \approx 655,302.857 $$
测试之下,这种模型的效果和 GPT-3.5 的能力比较接近,但是 GPT 3.5 的价格是 $0.50 / 1M input tokens [^4]。转换一下单位,他们一美元可以购买接近 2000000 个 token,比我们的 Token 多了接近 3 倍。在大规模服务之后,甚至可以使用 batch inference 进行一些加速和降本,OpenAI 可以将价格再降低一半。
算力讨论的意义
上面的公式确实可以粗浅估计我们如果自己维护类 GPT 应用的成本,但是我们的诸多计算建立在一个几乎不可能做到的基础上:我们的 GPU 时刻满载。我认为即使是 OpenAI,也不一定能让自己的所有 GPU 时刻满载用于服务客户,不同地区的服务器使用也有峰谷。
市面上的另一个品类是 GPT 的各种套壳站,这种业务之前价格一度上涨到离谱的数量级。如果我们不租赁 GPU,而是大量的代理服务器,用于免费转发 OpenAI 等公司的流量,将各种优惠策略累计,其实是可以达到一定程度的收益的。但是对体量、营销等方面都有非常高的要求。这个层面上更加类似传统的互联网项目,我在这里也不做过多讨论。
讨论算力也是为了讨论成本,从上面的两个路线的分析,不难得出一个结论:
2024 年的今天,直接提供通用型语言模型实现盈利基本不再可能。
基于这个结论,我们也应该认识到,大语言模型应该作为生产力产品中的一个环节,而不是产品本身。大语言模型本身并不是直接生产力,也不是有价值的互联网商品。只有经过定制化,对不同领域的特定问题进行调优之后,部署优化版本的模型提供服务,才具可能有盈利价值。
如果将全部的成本开销花费在 GPU 租赁上,无疑有些本末倒置。如果直接购买 AI 公司的 API,有些时候确实定制化程度不够,fine tune 的测试成本也非常高。那没有没有一种办法让我们可以更便宜提供定制化模型的服务呢?历史上,这个问题确实有一个解法。
云和 Serverless GPU
其实在传统的互联网产品中,数据库是一个广泛存在的需求。但是,分布式数据库中的产品中组件繁多,例如 kafka,redis,zookeeper 等,在生产环境中的部署是一个比较复杂的业务需求。在公司业务不够大之前,一个比较省钱的方案是直接购买云数据库。大量的 SaaS 业务的兴起也证明了这一点,微服务是一个非常有助于初创团队验证 idea 并且小规模测试的方案。
GPU 上云的难点
我们再次回顾一下我们的需求,因为客户数量的不确定性,我们对机器资源的分配和定制其实存在一定的困难。我们实际上需要的是一种可以根据用户数量弹性订购计算资源的系统。说到这一点,对云计算熟悉的朋友应该知道我说的其实就是 Serverless,其中代表性产品就是 Kubernetes,也就是所谓的 k8s。但是我们在大模型时代,成也 Serverless,败也 Serverless。
传统的 Serverless 业务中的一个重要环节是 cold boot,也就是常说的冷启动时间。简单来说:当一个应用场景中的用户数量增长超过现有机器的承载能力后,我们需要启动新的机器,配置上当前的业务程序去承载更多的用户。(当然,更准确的说法不是启动新的机器而是新的容器)
在经典的场景中:
Cold boot = 启动新容器的时间 + 容器和已有服务集群连接时间
但是,在 AI 场景中,我们的应用负载有了非常大的区别:
- 大文件:模型本身在这种环境下是一个必须的超大文件,这部分下载需要耗费大量的时间
- 新硬件:我们的容器中包含了 GPU 硬件,但是运行大模型的时候,我们真正用的并不是机器内存,而是 GPU 上的显存
- 启动复杂:传统应用启动之后,我们应用可以直接运行;但是作为 AI 应用,我们需要将模型载入 GPU
换而言之,现在 AI 时代的大模型应用:
Cold boot = 启动新容器的时间 + 模型下载时间 + 模型载入内存时间 + 模型载入 GPU 时间 + 容器和已有服务集群连接时间
上面的过程说起来可能不太直观,我们举一个具体的例子。同样,用上面的 Qwen2 作为例子,我们选一个看起来没有那么大的模型:Qwen2-7B-Instruct
运行代码可以参考 HuggingFace 上的最简单的例子:
# Use a pipeline as a high-level helper
from transformers import pipeline
messages = [
{"role": "user", "content": "Who are you?"},
]
pipe = pipeline("text-generation", model="Qwen/Qwen2-7B-Instruct")
pipe(messages)
模型的大小是 15 GB 左右,网速我们如果用 100MB/s 估算,时间开销大约是 150s 左右。但是这部分相对比较容易优化,这部分是网络和文件系统的直接交互,服务器上稍微增加一些开销提供一个分布式下载环境并不是难事。传统互联网公司对这方面也有对应的技术储备。
但是另一个问题就不太好解决了,模型载入 GPU 速度也需要加以考虑,开销大约是 6 秒左右。

如果说,每一个客户每次对话之前都需要等待时间少则 6 秒,多则 1 分钟,这显然是不可接受的,用户期待的是接近 0 延迟的效果。为了解决这个问题,大厂提供的方案是剥夺大家使用多样化模型的权利。典型的代表就是 OpenAI,提供少量的模型去给用户自由使用,这样他们只需要事先启动机器即可,不用考虑更换模型带来的开销。而另一方面的思路是做快速模型切换和快速模型拉起,最近几个月,这方面工作开始有逐渐变热门的趋势,不论是工业界的 kuberay[^5], Nvidia-GPUop[^6] 还是学术界的 ServerlessLLM[^7],都在这方面做出来一定的努力。目前这个领域的工业化也在不断完善推进,我认为这个领域 2-3 个月之内就会出现比较成熟的工业化方案,为更多的人提供定制化模型的系统侧基础设施会成为新一轮战场。提供 Serverless GPU 方案的厂商也在逐渐增长,其中比较有代表性的就有 banana[^8] 和 RunPod[^9]。随着这种部署模式的逐渐成熟,之后的竞争会逐渐激烈。
我的 AI 业务 —— 上不上云的决策
那么我们到底要不要上云跑自己的 AI 业务呢?
我这里用自己的几个 AI 业务作为例子。我作为一个独立开发者,本身的盈利能力非常有限,而且我其实有一些小小的公益追求,所以大部分的 AI 业务都是免费给大家使用的。控制成本是我部署业务的第一需求。
我想介绍的第一个项目是我自己的 AI 检索,基于 Perplexica[^10] 项目自己做了一些优化和改良。我的研究方向里面包含了一些向量数据库的研究课题,所以我基于自己的研究,改良了特定子领域的检索。例如我用自己的方案对 Wikipedia、arXiv paper 做了一些索引优化处理,在速度和精度上都做了一些提升。这里放一个效果(左侧为我的检索结果,右侧为 Perplexity Pro,为了更好的比较,冲了两个月的 Pro 会员,求个点赞回点血):
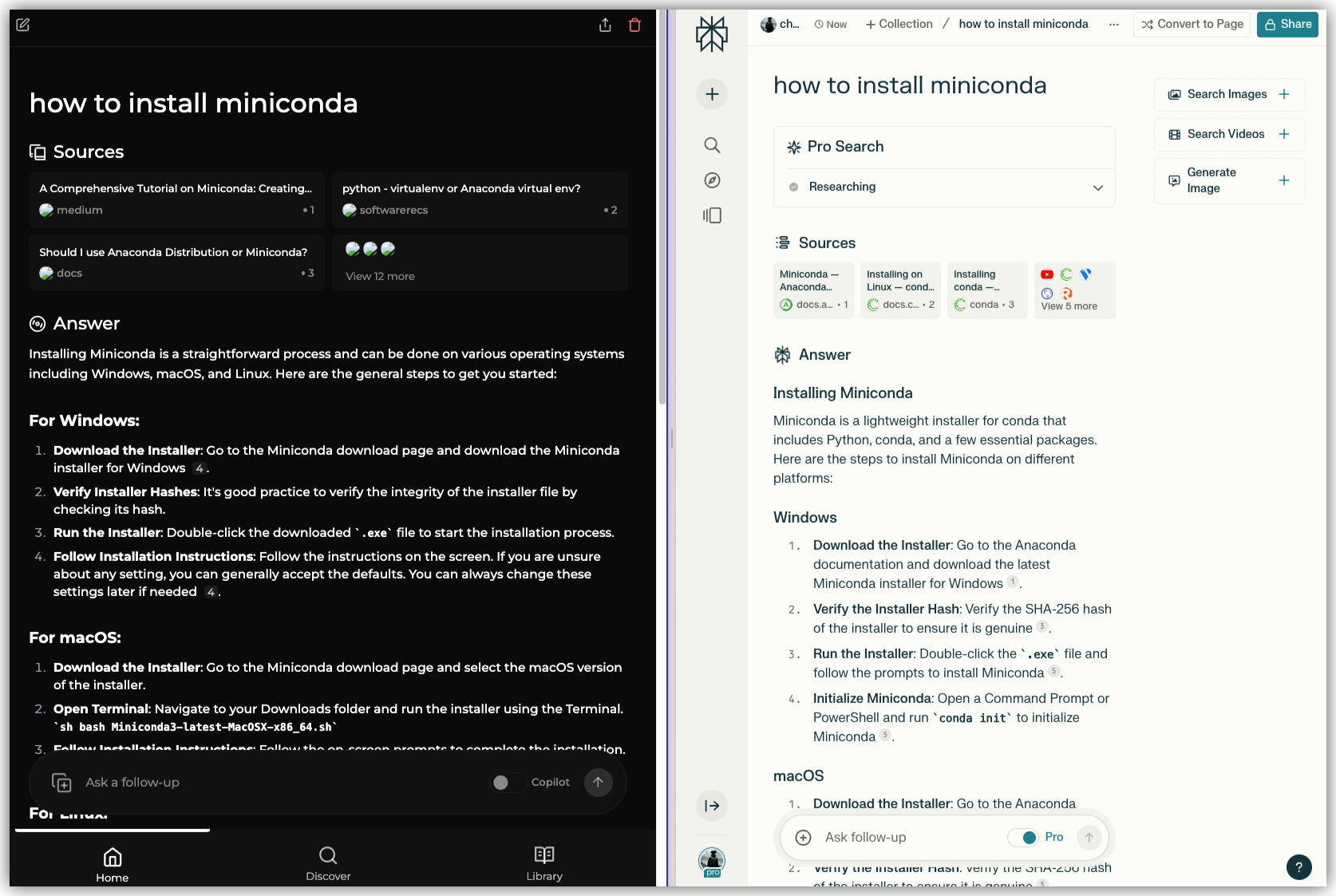
前面看起来似乎不相上下,但是后面的结果我的效果确实达到了更好的效果,在 Linux 系统的安装部分,经过我优化后给出的回答是:

包含了直接可用的脚本命令。而 Perplexity AI 的效果是:

单纯从效果上来看,目前我的优化已经超过了基础班,偶尔会比 Pro 版略胜一筹。这个产品目前还是免费运营的,只有我的一些熟人朋友免费使用,感兴趣的朋友可以随时给我邮件,欢迎大家免费使用。
那么这个业务我上云了吗?并没有,因为这个业务我们的搜索部分不需要使用 GPU,大模型部分使用综合能力较强的 API 即可,不需要使用定制化的模型。之后打算上云吗?确实会有需求,因为我对现在的效果并不满意,之后打算用自己微调的模型对搜索结果进行更合理精致的排序。
最近我的第二个业务是为了方便自己偷懒的业务,对计算机领域的科研党会有一些帮助。计算机领域每天会有 500-2000 篇不等的新文章发表在 arXiv 预印本平台上。为了跟进研究前沿,我每天都会用关键词筛选,选出自己感兴趣的论文。但是由于这个数字过于庞大,每篇都看我还是会异常头疼。所以我做了一个可以在当日论文中进行语义检索的工具:autoReader,小本生意,目前免费给大家使用。
这个业务上云了吗?其实云了一半。这个网站跑在「一个服务器 + 一台游戏本 + 三台办公笔记本」上。向量检索方案由于是我自建的,会经常魔改,所以不太方便上云,所以要放在游戏本上跑。对 PDF 文件进行 OCR 这种比较稳定的服务,我使用了配合方案,直接对学术论文的 OCR 工具非常少,所以我在 surya[^11] 项目对 PDF 文件进行切块。之后为了效率,租了一点 serverless GPU 处理这种 OCR 需求。这样能更及时地对客户进行消息推送。论文中的引用文献和图表加工调用了一些 GPT-4o 的额度,所以达到了非常好的检索效果。

现在还可以支持邮件订阅,即使是我自己搭的网站,我也懒得每天上去搜一遍,所以我自己做了一个订阅系统,自动检索我感兴趣的问题,把结果整理好发到我邮箱里面。
下一步计划就是继续提升文章的相关性排序,这部分不得不对现有的 rerank 方案进行深入理解和学习,可能还要对模型进行微调处理,让他们更好的理解「计算机领域研究的相关性」,某种意义上涉及到一些知识图谱的内容。不过我读博还有好几年,希望可以慢慢打磨好这个项目。(先挖一个坑,这个项目的完整架构近期会开源,并且会在这边再写一篇长文记录我搭建系统遇到的各种有趣的问题)
落地
这篇文章是我在飞机上完成的。OpenAI 最近发布了一些符合美式政治正确的言论,对中国和中国香港地区的 OpenAI 使用进行了严格的限制(虽然就没有正儿八经开放过)。我一时间思绪万千,这篇文章探讨的问题也就变得愈发重要了起来。
在我看来,中国的 AI 生态生长状态处在一个畸形的状态。我们在一个脆弱的基础上建立了一套虚伪的繁荣。在芯片资源受限的条件下,大厂之间的竞争变成了对私有数据的挖掘,构建各自的大模型。诚然,他们在不同领域各有千秋,但是有了计算资源和数据资源之后,这种工作的价值并不是那么惊艳。类比美国的产业结构,除了大量的 AI 产品服务商,OpenAI 和住多厂商也开放了 Fine Tune 和开发者平台,允许开发者进行二次定制;AWS 和前文提到的 banana 提供了 Serverless 的 GPU 业务方便没有设备的开发者快捷开发,也提供了让他们产品可以落地的部署平台。上述这两点对应的生态位在国产大厂中是非常稀缺的,这也是我对开篇问题给出的答案,限制 AI 产品发展的,其实是我们在异构计算时代,廉价云计算基建的缺失。
在 AI 竞争白热化的今天,大模型为大众带来的便利和创新是史无前例的。但是目前看来,大模型并没有达到我期待的样子。定制大模型需要资源,具体说是专家和显卡,而这部分人的圈子逐渐封闭,构建了一个新的阶级。大模型的供应,从来就不应该被垄断在寡头手里。芯片禁令、闭源模型、私有数据、设备限制,这些政策和问题更是助纣为虐。
作为一个从事 AI 相关行业的从业人员,最能深刻感受到这个时代的春江水暖。我深刻感受到我们的创造力和生产力都被 AI 充分激发,每个人都有了点燃时代烟火的权利和机会。我希望这个时代,每个有机会去点燃烟火的人,都生而平等。
最后引用一下以为我喜欢的作家书中的一句话,聊以书心述道:
我要这天,再遮不住我眼;要这地,再埋不了我心;要这众生,都明白我意;要那诸佛,都烟消云散。
(题外话,给自己挂个广告,如果有需要部署或者定制特定场景的大语言模型产品,欢迎给我私信或者邮箱联系,备注上少数派 ID。给咱派友提供免费咨询。)
[^1]: https://antfu.me/posts/ai-qrcode-101 AI QR Code 生成 101 [^2]: https://openai.com/api/pricing/ OpenAI 计费 [^3]: https://chat.lmsys.org/ GPT Arena 排行榜 [^4]: https://openai.com/api/pricing/ OpenAI 定价 [^5]: https://github.com/ray-project/kuberay Kuberay [^6]: https://github.com/NVIDIA/gpu-operator GPU operator [^7]: https://arxiv.org/abs/2401.14351 ServerlessLLM [^8]: https://www.banana.dev/ Banana.dev [^9]: https://www.runpod.io/?inflect= RunPod [^10]: https://github.com/ItzCrazyKns/Perplexica Perplexica [^11]: https://github.com/VikParuchuri/surya surya