
从 2024 Google IO 看下一场竞争

这是一篇简单粗暴的技术短报,简单聊聊我在今年在 Google IO 上看到的一些有趣的事情。
Edge device
今年最大的感触是 AI 上端测的事情。今年大量的 workshop 和展厅对端侧 AI 进行了讨论和部署。其实一个有意思的事情是,我们端侧的 AI 应该怎么部署。我觉得短期内,这个问题是没有答案的,只有具体的产品出现之后才能对产品进行精准的评估。
路线之争
回顾一下当代神经网络的开发模式和部署模式,不难发现我们最常用的生态是基于 Python 语言的环境,和基于 Tensorflow/Pytorch 的架构。而这两大生态在端侧上是极为缺失的。
大概 8 年前,我还在用塞班系统的时候,那会儿手机上没有微信和 QQ,但是上了大学了,我多少还是要用这种「必要社交软件」的。所以当时找到了别人做好的 Python 2.7 部署方案,基于 request 包写了消息转发系统,勉强弄了个可以收发微信消息的套壳工具。从那个时候我就发现整个系统的瓶颈在 Python 的解释性执行模式。
这么多年过去了,我日常用的最多的 Python 版本也升级到了 Python 3.10。但是这个故事还是如此。这个困难的本质其实在于我们的开发环境和部署环境是完全异构的。我们回顾一下传统的软件开发生态,其一是 An#droid 原生 App 开发,我们是在 emulator 上完整测试之后,直接进行打包的;其二是服务端的一些产品,我们在本地测试完成之后,直接在服务器上拉取部署。这两种开发形式中,开发平台和部署平台有一样的开发环境,更重要的是拥有同一套运行时环境,也就是所谓的 runtime。
而二十多年前我们在多端协同的时候也遇到了一样的问题,这个时期为了保证应用的移植便携,我们使用一定程度的性能作为代价,得到了一些振奋人心的产品,其中最有代表性的便是 Java 和 .NET。在偏向 to C 业务的应用层面,性能确实不是最重要的问题,可用性和便于移植才是。
那么这个时候我们就会想,既然问题已经这么明确了,我们为什么不直接在移动端做一套 python runtime 呢?
关于这个问题,其实一直以来都有人在为之付出努力,但是我们在移植 AI 应用的时候,本质上移动的不是简单的 Python,而是基于 Torch/Tensorflow 的深度学习运行环境。不论是 PyTorch MOBILE 还是 TVM 其本质上都是在解决这个问题。端侧设备比起我们的 CPU + GPU 异构开发模式,我们可用的计算资源非常有限。但是好消息是,我们需要移植的应用往往不需要我们移植全部的深度学习框架代码,我们只需要关注我们应用需要使用的特定数量的算子,就可以完成应用移植了。
这条路线上,其实我比较喜欢的是 Microsoft 的 ONNX 框架,这个模式提供了复杂深度学习应用的部署思路:转换成计算图,之后在各个平台上实现对计算图的计算引擎。这种思想其实也是也就部署的主流,不论是 Pytorch Dynamo 还是 TVM 其实都是在计算图上进行优化和加速。而我最近其实也在思考这条路线的合理性,我们回顾一下我们在上个时代遇到的问题,我们显然发现,这些框架追求的是端侧的执行效率,而不是端侧的便于移植和部署。
这个时候,我们不得不回头思考一下,有没有什么运行时环境,可以充分利用手机的硬件性能,便于移植,在各个平台上都能流畅执行呢?想必大家已经猜到答案了,那就是浏览器。Web 端应用可以用最低的成本完成对应用的部署。虽然效率上我们有一些不尽人意的地方,但是这种便于移植的特性短期内是很难被超越的。尽管我们有 Flutter 和一些全平台的开发环境,但是单论「可以在端侧设备上使用加速器件」这件事情,Vulkan 和 WebGPU 确实有目前位置不可取代的生态位。
从这次的 Google IO 展会上也能看到这类技术的影子,目前已经有人试着用浏览器内核去执行 1B 或者 2B 这种小模型了。此外,以 Tauri 为代表的 Webassembly 也为更低延迟和更高性能做好了前置准备。所以从工程角度上来看,我觉得半年内是有希望看到一个在 WebGPU 上的可靠 7B 模型方案的。
那么我们的路线到底会从图编译执行引擎走向 WebGPU,还是会从 WebGPU 走向图优化呢?我个人倾向于后者的发展,目前 WebGPU 处在一个聊胜于无的状态下,而且其最初的设计目的也不是为了服务高性能的 AI 业务。我之所以认为这条路线可行,是因为近期的 GPU.cpp^1 项目让我看到了如何用好 WebGPU 其实可能并没有那么难。
说了这么多,我们整理一下现在的思路:
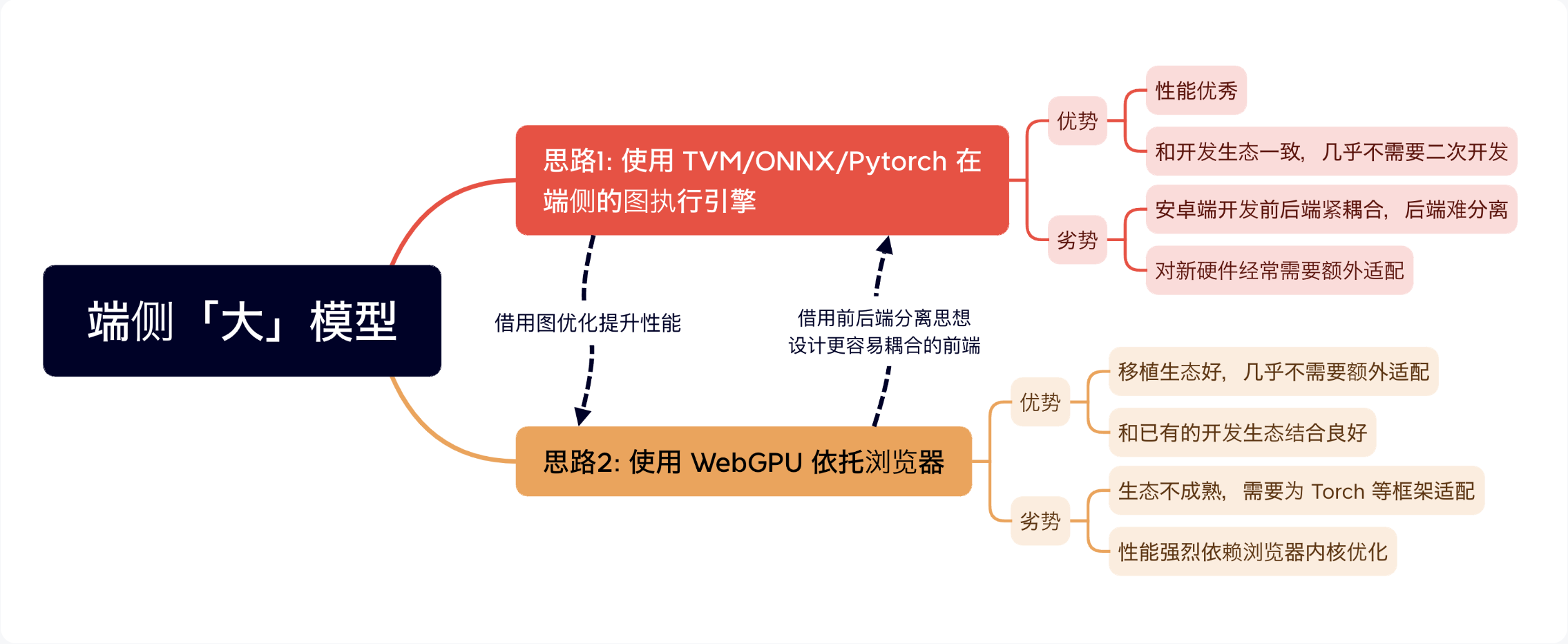
上面两条路线很难说孰优孰劣,从思路上看,前者更适合学术研究,因为模块独立干净,更适合做性能分析。后者更适合工业开发,和产品端更接近。前者,我们需要的可能是「端侧 Python 为基础的前端框架」;后者我们需要的可能是「基于 WebGPU 框架的性能分析工具和图优化工具」。从模型开发的角度上分析,我们需要一个从「Pytorch 到 WebGPU 框架的翻译工具」,才能让学术产品更快地落地到应用层。
端侧的爆发
从最近的科研趋势来看,越来越多的开源项目也开始尝试便捷的移动端测模型部署方案。除了上面的两种方案之外,为特定模型定制各种端测的部署方案也收获了很多社区关注,其中最有代表性的工作无疑是 whisper.cpp^2 和 llama.cpp^3。在各种端测实现了极致的推理速度。但是将他们作为模块整合到现有 app 中,或者结合到目前的端侧开发方案,这两者其实距离实际生产有很远的距离。
除了上述的两个项目之外,近期学界比较收到关注的是 T-MAC^4 项目。在端测实现了 5-8 倍的推理速度,让大模型直接变得可用。社区方面,近期 TORCHMOBIL^5 和 LLMMLC^6 也收获了大量的关注,近期项目的 Star 数目飞速增长。这种趋势让我看到端侧的战争已经开始,如果说 PowerInfer^7 是端侧部署竞争的第一枪,那么现在端侧竞争也正式进入白热化状态。
作为学界的从业者,我自己想做的,也是换了 1 加的设备,想试试 24GB 的内存可以带来什么样的可能性。工业界的朋友其实也不必焦虑,正如上面所说,目前的路线之争也还没有完全定论,而且我认为上面的两条路线其实都可以很好的生存下来。两条路线的关系甚至有一些像 React 和 Vue 的关系,两者也会互相学习借鉴,但是有着共同的终极目标。
端侧模型现在看起来我们已经基本解决了速度方面的问题,但是我们还有更多基础问题没有很好地考虑,例如模型效果在量化或者使用替代算法会急剧下降,以及模型内存开销仍然需要更严格的控制。软硬件协同发展的路上,我们很容易发现一个臃肿的现实,不论硬件我们取得多大的突破,我们软件都会很快将硬件带来的性能红利消耗殆尽。不论多么好用的电脑,过个三五年,还是容易卡顿。现代化的 3D.js 和 Vulkan 发展之后,现在的网页效果越来越炫酷,更有各种 WASM 的应用可以使用。所以我几年前还在电脑维修店兼职的时候,听到最多的一句话就是:「我现在开个网站都卡」。所以说,我们理论上有更大的内存,更快的计算设备,但是真正能分配到模型上的使用空间可能远比我们想象的要小。这也是我认为端侧大模型在工业界短期不容易落地的原因,并不是应用本身的问题,而是要和已有的生态环境兼容妥协,才能获得真正可用的版本。
端云协同的边界
那么我们有了端侧还要不要云端呢?
目前看来还是必须的,端侧设备上目前还没有办法带动 70B 及以上的模型,甚至 13B 都非常费劲。在我之前的文章里讨论过,多模态场景下,我们端云协同的意义。其中一个重要因素是可以通过对复杂模态的「编码」和「描述」,从而降低网络带宽的负载。例如在音频笔记软件中,我们传输音频的开销是比较大的,但是端侧使用 whisper.cpp 直接进行转写,那么流量大约可以节省 2-3 个数量级,而且效果其实并不会收到太大影响。
不过,这个时候隐私、安全和面对大模型的加密算法可能会成为下一个 10 年安全领域的重要讨论话题。这里也不是我关注的课题,但是对业界的启发是:「部署自己的私有云,利用有限计算资源去服务多种 AI 模型」这条路线目前看来会长期具有战略意义。
浅谈 AI 出海
谈完了端侧的看法,我这次还简单看了一些 Google IO 出海计划。我个人非常喜欢这种业务,让我看到了现在 AI 应用的可能性,也让我看到了 AI 应用其实有很多选择。纠正了一些我之前的片面认识。
出海的应用中,其实大多数也是 text to image,chatbot,或者风格迁移之类的应用。但是对「特定地区或人群进行适配」、「用产品积累的宝贵数据进行微调」两点,确实让我看到了这个赛道的另一种打发。即通过先发优势和时间积累,在一个方向上积累数据,对这些数据进行深度发掘和二次利用进行产品迭代。我之前对 AI 产品的要求确实过于苛刻了,而这次出海的产品让我看到,AI 真正给应用成功赋能,让他们可以在某一时间很好地为一类人服务。这种模块化并且 ad hoc 的设计有违我的个人理念,我是一个教条的完美主义者,但是我对这些产品确实都挑不出毛病。只要能落地,能解决问题的模型就是好模型。
小结
今年的 Google IO 让我确实看到了一些 AI 破局的方法。小模型在端侧的部署提醒了我需要认真思考端云协同生态的开发模式;而量化大模型的部署也提醒我需要为下一个 5 年提前进行相关技术储备。在书桌前看 paper 久了,对世界的认知会有偏差,会感觉现在的 AI 已经可以托管一切了。而开发者大会会看到更多脚踏实地的开发者,用努力一点一点为我们拓展技术的边界。最后,期待明年的 Google IO!
References
[^1]: https://github.com/AnswerDotAI/gpu.cpp
[^2]: https://github.com/ggerganov/whisper.cpp
[^3]: https://github.com/ggerganov/llama.cpp
[^4]: https://github.com/microsoft/T-MAC
[^5]: https://pytorch.org/mobile/home/
[^6]: https://llm.mlc.ai/
[^7]: https://arxiv.org/abs/2406.06282